|
I am co-founder and researcher at Ideogram AI . I was previously Senior Research Scientist at Google Brain, Toronto. Before that, I completed my undergrad from Indian Institute of Technology (IIT), Bombay with a major in Computer Science and Engineering . Previously, I interned at Mila, Montreal under the supervision of Prof. Yoshua Bengio , and Dzmitry Bahdanau . Email / CV / Google Scholar / Twitter |

|
|
Currently, I am working on high-resolution controllable text to image generation at Ideogram AI. My work spans the full stack of model research and development, including pre-training, post-training, large-scale data processing pipelines, and serving models to millions of users. |

|
Jonathan Ho*, William Chan*, Chitwan Saharia*, Jay Whang*, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David J. Fleet , Tim Salimans* Pre-print arXiv / Page We present Imagen Video, a text-conditional video generation system based on a cascade of video diffusion models. Given a text prompt, Imagen Video generates high definition videos using a base video generation model and a sequence of interleaved spatial and temporal video super-resolution models. |

|
Su Wang*, Chitwan Saharia*, Ceslee Montgomery*, Jordi Pont-Tuset, Shai Noy, Stefano Pellegrini, Yasumasa Onoe, Sarah Laszlo, David J. Fleet, Radu Soricut, Jason Baldridge, Mohammad Norouzi, Peter Anderson, William Chan Computer Vision and Pattern Recognition (CVPR), 2023 arXiv / Page We introduce Imagen Editor, a state-of-the-art solution for the task of masked inpainting — i.e., when a user provides text instructions alongside an overlay or “mask” (usually generated within a drawing-type interface) indicating the area of the image they would like to modify. |

|
Chitwan Saharia*, William Chan*, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet , Mohammad Norouzi* Neural Information Processing Systems (NeurIPS), 2022 (Outstanding Paper Award) arXiv / Page We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. |

|
Jay Whang, Mauricio Delbracio, Hossein Talebi, Chitwan Saharia, Alexandros G. Dimakis, Peyman Milanfar Computer Vision and Patter Recognition (CVPR), 2022 (ORAL) arXiv We present a framework for blind deblurring based on conditional diffusion models. Unlike existing techniques, we train a stochastic sampler that refines the output of a deterministic predictor and is capable of producing a diverse set of plausible reconstructions for a given input. |

|
Chitwan Saharia, William Chan, Chris A. Lee, Huiwen Chang, Jonathan Ho, Tim Salimans, David J. Fleet* , Mohammad Norouzi* SIGGRAPH, Conference Track, 2022 Workshop on Deep Generative Models and Applications, NeurIPS, 2021 arXiv / Page We introduce Palette, an image-to-image translation model that leverages diffusion generative models. We show strong performance of Palette on colorization, inpainting, uncropping and JPEG artifact removal. We apply Palette to these tasks without any task-specific tuning of the loss function or architecture and show that Palette beats several strong task-specific GAN and autoregressive model baselines. |

|
Jonathan Ho*, Chitwan Saharia*, William Chan, David J. Fleet, Mohammad Norouzi, Tim Salimans Journal of Machine Learning Research (JMLR) , 2022 arXiv / Page We show that cascaded diffusion models are capable of generating high fidelity images on the class-conditional ImageNet generation challenge, without any assistance from auxiliary image classifiers to boost sample quality. We outperform BigGAN-deep and VQVAE-2 on FID and classification accuracy scores (CAS). |

|
Chitwan Saharia, Jonathan Ho, William Chan, Tim Salimans, David J. Fleet, Mohammad Norouzi Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2022 arXiv / Page We adapt score matching based diffusion models for the image super-resolution. We achieve a fool rate of 50% on face super-resolution, and 40% on ImageNet super-resolution. We cascaded multiple super-resolution models to efficiently generate 1024x1024 unconditional faces, and 256x256 class conditional natural images. |
|
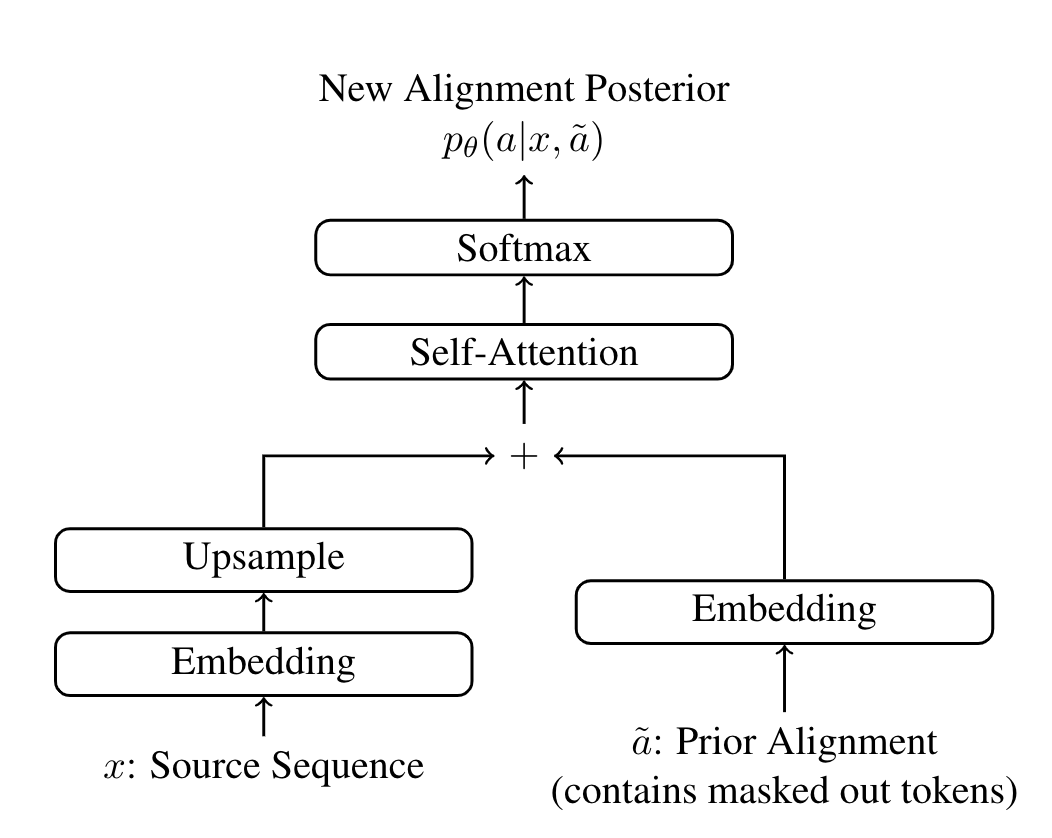
Chitwan Saharia*, William Chan*, Saurabh Saxena, Mohammad Norouzi Empirical Methods in Natural Language Processing (EMNLP), 2020 arXiv / Talk We apply latent alignment based models for non-autoregressive machine translation. We achieve SOTA for WMT14 EnDe for single step generation using CTC, and SOTA for iterative generation using Imputer. |

|
William Chan, Chitwan Saharia, Geoffrey Hinton, Mohammad Norouzi, Navdeep Jaitly International Conference on Machine Learning (ICML), 2020 arXiv / Talk / Media We introduce a semi-autoregressive model for speech recognition that uses a tractable dynamic programming algorithm to approximately marginalize over all latent alignments and generation orders. |

|
Konrad Zolna*, Chitwan Saharia*, Leonard Boussioux*, David Yu-Tung Hui, Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Yoshua Bengio Association for the Advancement of Artificial Intelligence (AAAI) Student Abstract, 2020 (Extended Version) NeurIPS Deep RL Workshop, 2020 and IJCNN (ORAL), 2021 arXiv / Poster We study the impact of False Negatives in GAIL algorithm, and present a method diagnose it. We further present a solution - Fake Conditioning and improve upon sample complexity of human demonstrations by an order of magnitude compared to Behavioral Cloning. |

|
Pankaj Joshi*, Chitwan Saharia*, Vishwajeet Singh, Digvijaysingh Gautam, Ganesh Ramakrishnan, Preethi Jyothi Workshop on Multi-modal Video Analysis and Moments in Time Challenge, ICCV, 2019 Paper / Poster We study the impact audio and visual modalities in learning models for Video Captioning. |

|
Maxime Chevalier-Boisvert, Dzmitry Bahdanau, Salem Lahlou, Lucas Willems, Chitwan Saharia, Thien Huu Nguyen, Yoshua Bengio International Conference on Learning Representations (ICLR), 2019 arXiv / Code / Poster We present a platform to study sample efficiency of grounded language learning. We include a numer of tasks with varying complexity and present a rigid sample complexity benchmark on each task. |
| Imagining with Imagen |
| Talk on Diffusion Models @ CS391L, UT Austin |
| Talk on Imagen (AI4CC @ NeurIPS, 2022) |
Huge thanks to Jon Barron for the template! |